Datamodels¶
Datamodels are the core data processing units of 3forge. They are static tabular representations of some underlying data from a datasource, such as an SQL database, realtime feed, etc.
Accessed in the Data Modeler, datamodels are your main source of visualizations and blending across multiple datasource types.
Overview¶
Datamodels are created via the Data Modeler, which can be accessed either directly from a panel or through the top menu in Dashboard -> Data Modeler.
Datamodels are built when 3forge is initialized, or each time the creation wizard is run, and sit in Web receiving information from the Center, datasources, or feeds.
Generally speaking, datamodels are static representations of underlying data, but 3forge does have "realtime datamodels" which emulate real-time behavior by periodically updating. These settings can all be established in the datamodel creation wizard.
Datamodel Threading¶
The order of execution of datamodels and their creation is managed by the 3forge session. Each instance of 3forge is composed of three threads:
- Front end UI callbacks/ GUI
- Datamodel processing
- Backend and real-time data processing
All datamodels in a given 3forge instance are managed by a single thread. Running a datamodel means any other pending datamodels are added to a queue.
If the thread encounters an EXECUTE statement, 3forge will pause the current datamodel and check the next datamodel in the queue, while periodically re-checking the original datamodel for a response to the EXECUTE statement.
Note
EXECUTE statements can be run asynchronously. See this reference page for more information on deferred statements in 3forge and how to use them for performance gains.
Datamodels are a powerful tool enabling users to create highly blended visualizations, however can be computationally expensive to run repeatedly, especially if you have several datamodels.
In some instances, you may prefer to use realtime tables instead. A comparison of the two can be found on this page.
See this section on configuring datamodels to rerun.
Creating Datamodels¶
To create a datamodel, either right-click on a blank portion of the Data Modeler, or navigate to a datasource and right-click on the datasource and click "Add Datamodel".

Within the datamodel creation tool, you can input any valid AmiScript to determine the logic behind a datamodel, including calculations, joins, or any other analytics.
Selecting and Querying a Datasource¶
To specify a datasource, if any, for the datamodel to be built on, select the datasource in the field at the bottom of the datamodel creation wizard:
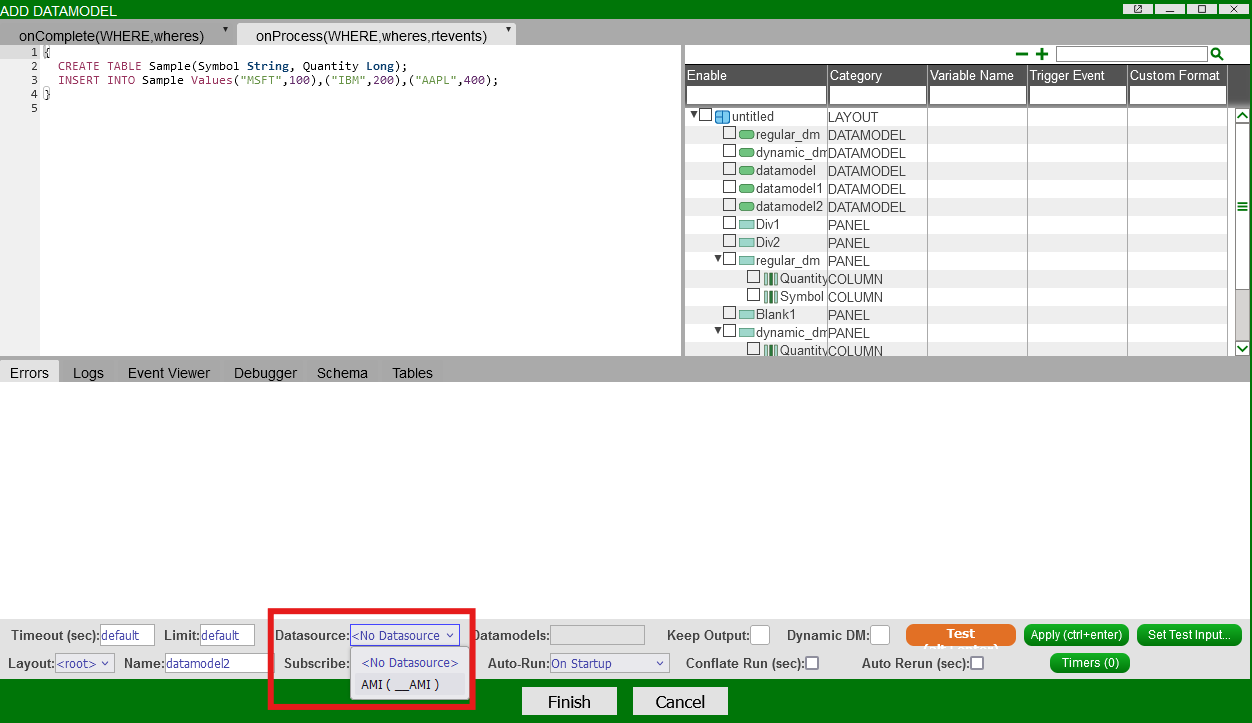
If the datamodel needs to fetch data directly from a datasource, you will need to send an EXECUTE clause to query that datasource.
- The
EXECUTEclause allows a user to pass an external command formatted for the intended datasource. For example, a MySQL datasource must have SQL commands in the query:
Note
You can also specify a datasource programmatically in AmiScript by using the AMI SQL USE command, e.g:
CREATE TABLE sql_table AS USE ds="some.datasource" EXECUTE SELECT * FROM my_sql_table;
This also allows for multiple datasources to be called in the same datamodel. This example shows how to use a datamodel to insert data from one datasource to another.
Keep Output¶
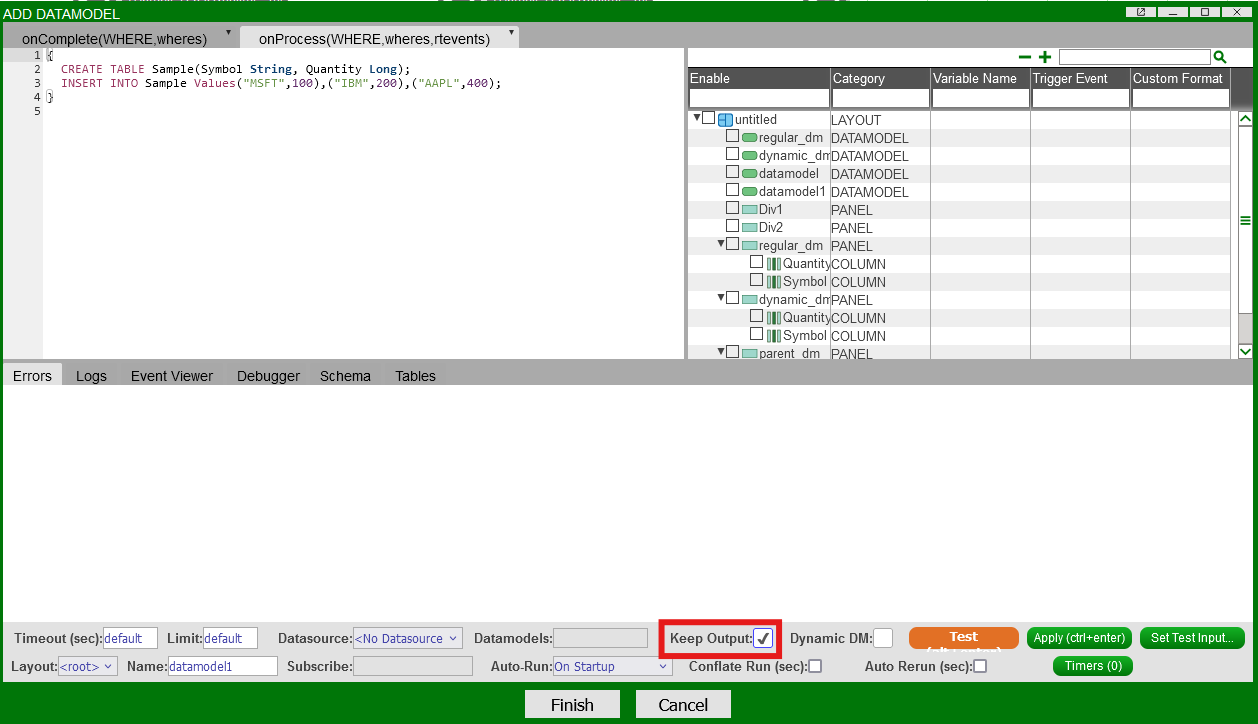
Toggling the "Keep Output" option causes the datamodel to carry over the result from its last run.
For the above datamodel, without "Keep Output" checked, each time the datamodel runs, it will create a new table called "Sample" and insert 3 rows.
With "Keep Output" selected, the datamodel will not create a new table. Instead it will keep inserting the same 3 rows.
Dynamic DM (Developer)¶

Toggling the "Dynamic DM" option will propagate schema changes from the parent datamodel to its children. If not checked, the blender will remain unchanged schema-wise, but will update when new data is added to the parent datamodel.
You will also need to enable auto-update columns to ensure changes are propagated in the visualizers.

Note
Dynamic DM is not available in all versions of 3forge. Please contact us at support@3forge.com if this is a requirement.
Example¶
- Consider the following datamodel:
-
It is possible to create datamodels from other datamodels, known in 3forge as "blenders." These can be treated like any other datamodel, including visualizations. They are used for blending data from multiple sources into the same datamodel.
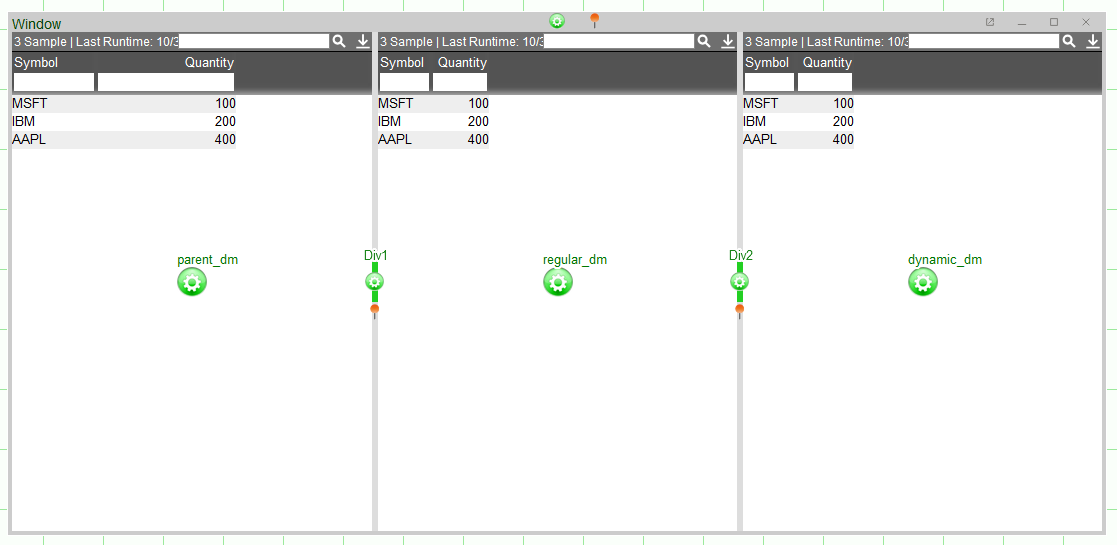
Here, each datamodel contains the same data but the children datamodels,
regular_dmanddynamic_dm, are blenders of theparent_dm. The underlying architecture for these panels and visualizations can be seen here: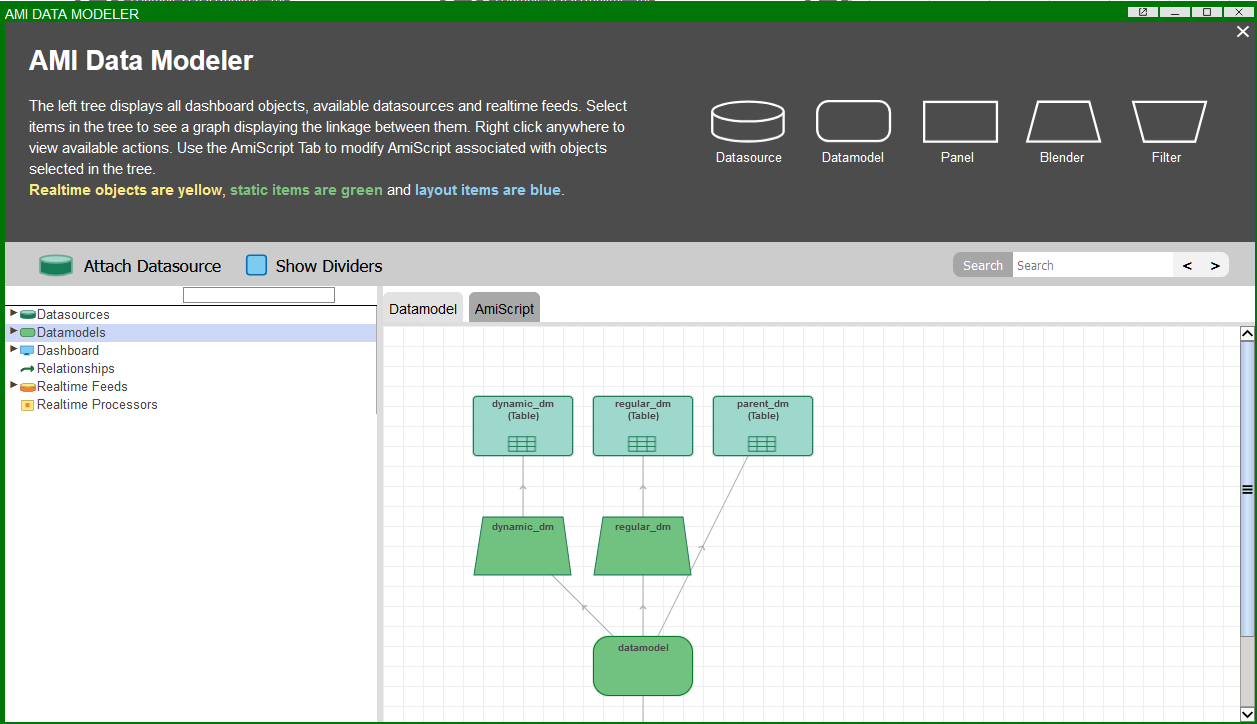
The panel
dynamic_dmcontains a visualization built on a datamodel which has "Dynamic DM" checked. Updating the schema of the parent datamodel will also update the dynamic datamodel's schema, but not the regular one.
Testing Datamodels¶
Datamodels are highly customizable and can contain complicated user-written code. Upon finishing datamodel creation, users will be prompted to test their datamodels:
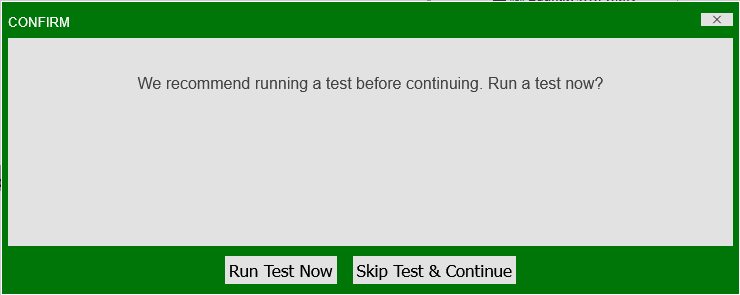
Testing datamodels is useful for several reasons including but not limited to:
- Verifying that user code is valid
- Identifying latency issues
- Ensuring that any external datasources are being correctly queried
Testing executes and displays the output of the selected datamodel callback (onProcess() or onComplete()):
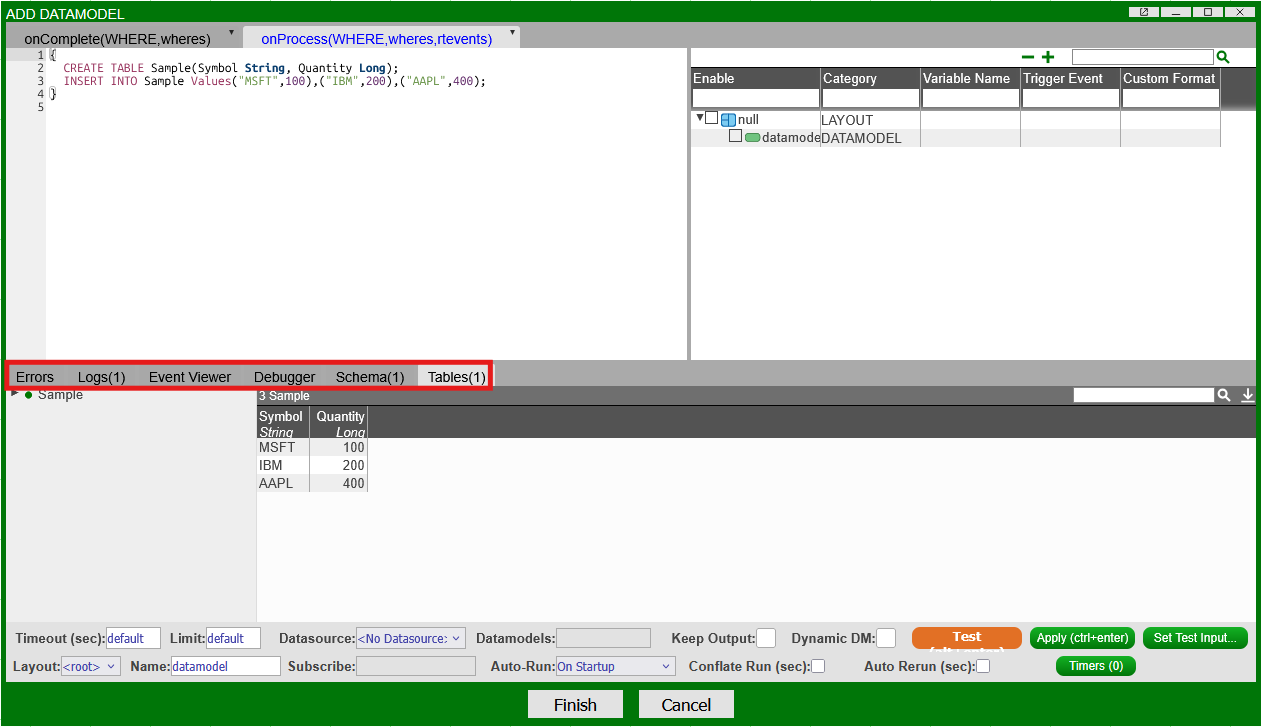
Each heading can be selected and their respective outputs viewed.
Note
This feature only tests the datamodel based on the state of the datamodel wizard. Any external calls to the datamodel, e.g: in a separate panel, will not be tested.
To test different conditions, you will need to change the datamodel callback's test inputs. See the instructions below.
Datamodel Inputs¶
Executing datamodels will trigger the onProcess() and onComplete() callbacks. These callbacks take parameters, or inputs, that the datamodel is run on. By default, these values are:
String WHERE: trueMap wheres: nullRealtimeEvent rtevents: null
To test different input values in the datamodel wizard, users can either:
- Use the AmiScript windows (hard-code test cases)
- Use the "Set Test Input..." button
Example¶
- Assuming you have following basic datamodel (in
onProcess()): -
To test the
WHEREclause in "Temp":-
In the
onProcess()AmiScript window, create a String to store theWHEREclause: -
Running "Test" with the
WHEREclause will output the following: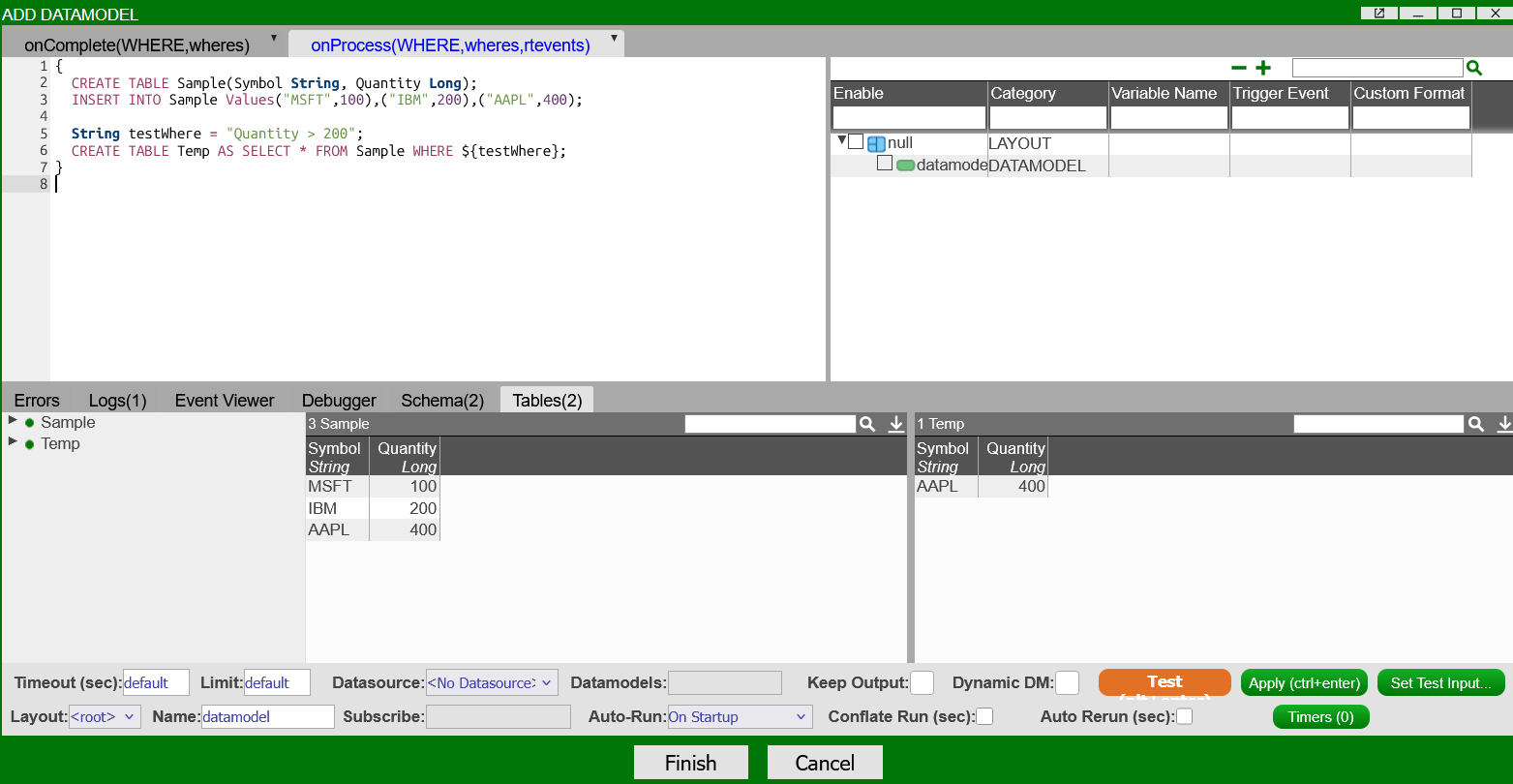
Note
If you submit the datamodel at this stage, any changes to "Temp" will be propagated as it is hard coded.
Either press "Cancel", or comment out test clauses.
-
At the bottom right-hand side of the datamodel wizard, click the "Set Test Input..." button:
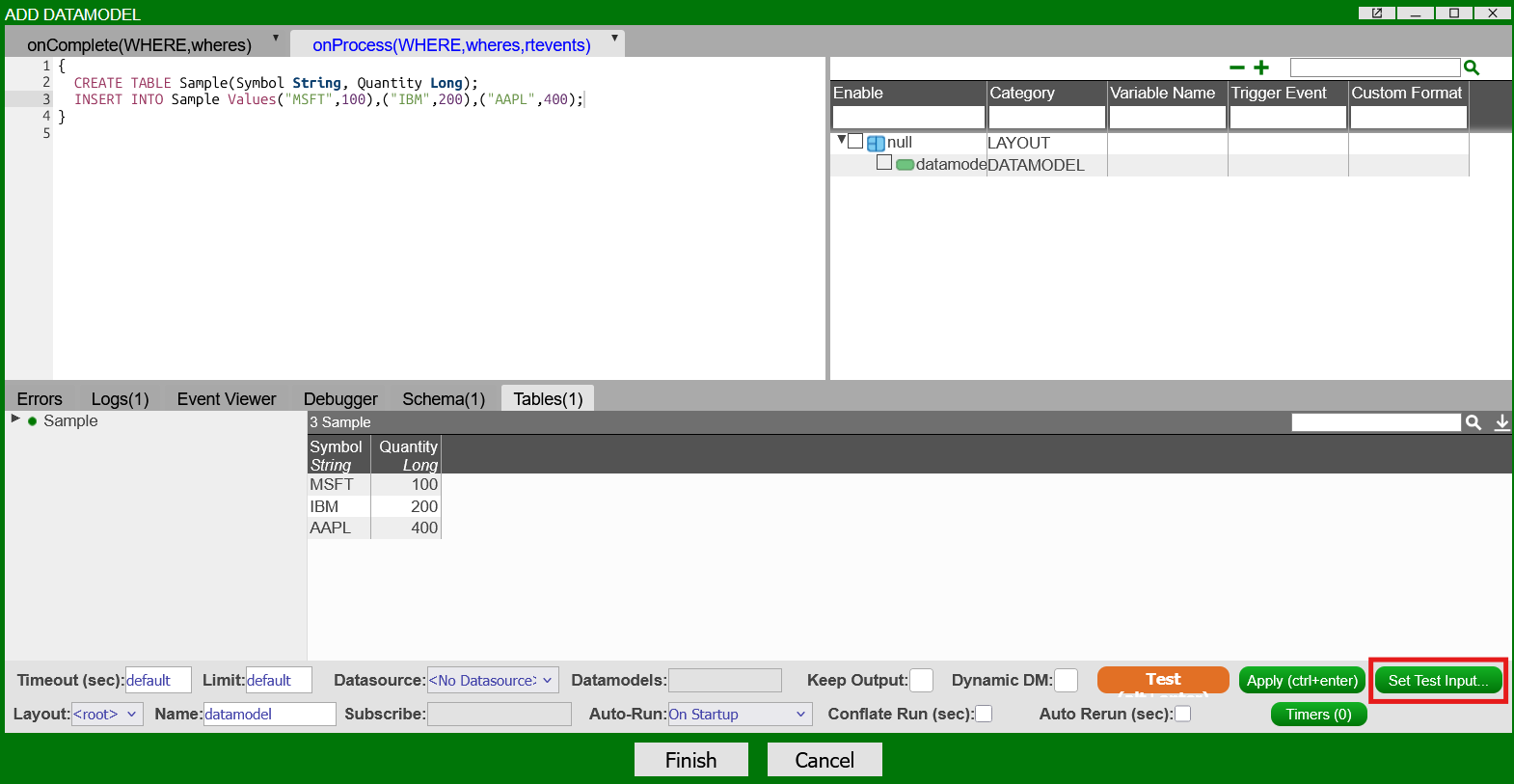
-
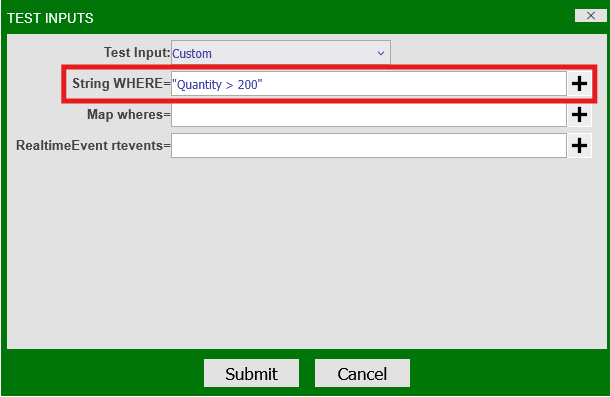
Change the "Test Input" dropdown selection to "Custom." In the "String WHERE" input, enter "Quantity > 200" and press "Submit":
-
Running "Test" will now run the
WHEREclause using the Test Inputs that have been set: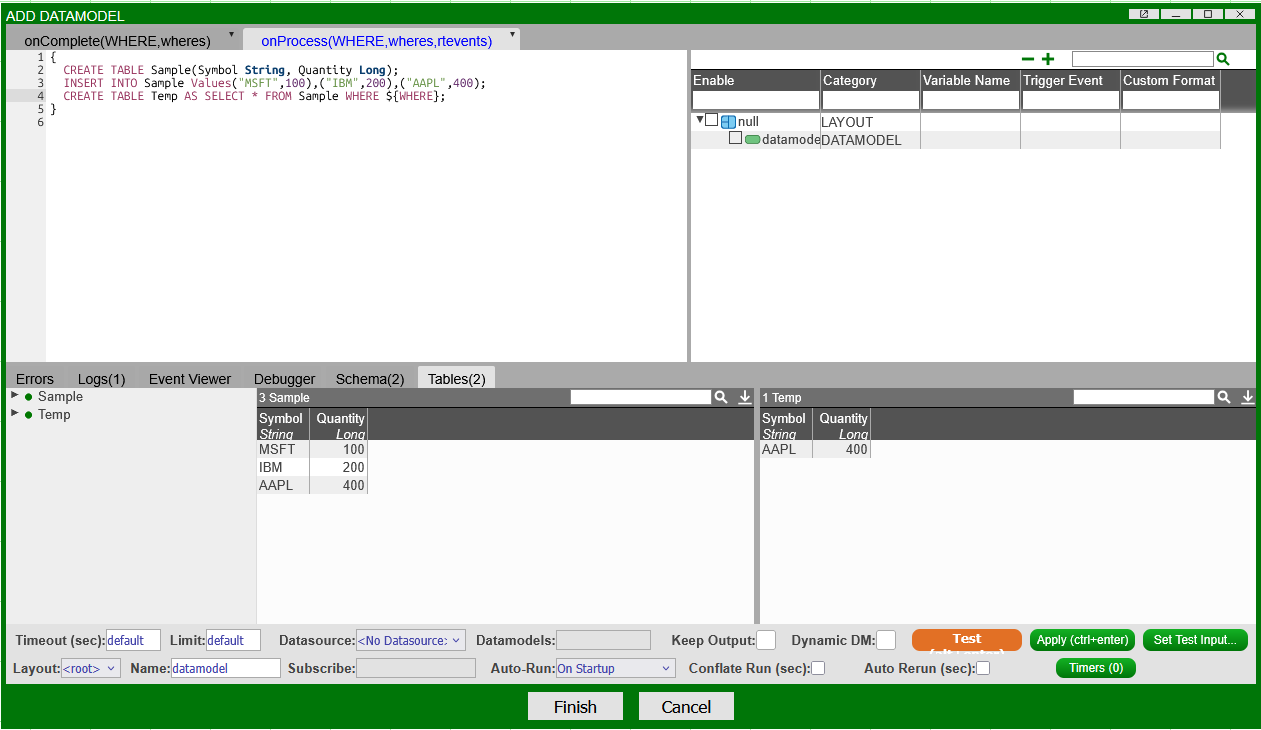
Both cases will output the same table "Temp" on testing.
-
Inserting From Datamodels¶
A datamodel can be used to join data from multiple datasources with the USE ds option. The example below shows how to insert data from one datasource to another with a datamodel.
Example: Copy a Table Into AMI Center¶
There are two datasources:
- AMI (the default datasource and corresponds to the Center)
- WORLD (SQLite)
This example looks to copy a table named "Country", which exists in the "WORLD" datasource, into the "AMI" datasource as a Center table.
- Create a datamodel that is attached to the "WORLD" Datasource.

Within the onProcess() callback, we want to achieve the following:
- Create the "Country" table
- Get the schema of the "Country" table
- Build that table in AMI Center
- Use the AMI Center as the datasource for displaying the data
- The AmiScript below can be copied with comments explaining each step.
- This will now give you the Country table in the 3forge datasource:

Realtime Datamodels¶
Datamodels can be run to update in pseudo-real-time, referred to as "realtime datamodels."
The primary difference between realtime and regular datamodels is how information is passed to the datamodel. Realtime datamodels subscribe to a feed and are rerun either when changes are pushed to that feed, or after a specified time slot. This functionality mimics true real-time behavior and can be useful for certain types of visualizations.
Realtime datamodels are created through the same datamodel creation wizard as static datamodels.
Realtime Feeds vs Datasources¶
Realtime feeds are data streams that are passed to and hosted on AMI Center as Realtime Tables. Any Center table can act as a realtime feed.
External data can be passed into AMI via a number of routes, but are typically from feed handlers or through the AMI Client.
Example: Display Top 3 Items From a Feed¶
Assume there is a realtime feed transaction(TransactionID Long,sym String,price Double):
-
Create a datamodel called "realtimeDM" via the creation wizard. At the bottom of the screen, click on the "Subscribe" field to open a drop-down menu of available real-time feeds. Select the
transactionfeed.
-
Within the datamodel
onProcess()callback, configure a query to display the top 3 symbols with the highest total price:
To control how frequently the datamodel should rerun and refresh, set the "Conflate Run" parameter.
In this example, it is set to 10 seconds, which means the datamodel will wait 10 seconds before reprocessing.

-
Create a realtime visualization panel off of the realtime datamodel that we just created
In this example, we created a real time heatmap off of the top3sym table.


-
Final Heatmap

Note
You can press space on the heatmap to zoom in/out.
The onProcess() Callback¶
Most datamodels are run once when AMI starts up. This triggers the datamodel callback onProcess(), which is the main configurable AmiScript window in the datamodel creation wizard. This is where users define the primary logic of the datamodel.
Note
Testing, or editing a datamodel and submitting "Finish", will also rerun the datamodel and cause it to reprocess.
Datamodels are generally intended to be static and fetch data from an external datasource by sending executable queries to that datasource. A user can however trigger a datamodel's onProcess() callback to be called again by doing the following:
- Calling the
datamodel.process(),datamodel.processSync(), ordatamodel.reprocess()methods. - Manually running a datamodel wizard again.
- Using "Conflate Run" and/or "Auto Rerun"
Conflate Run vs Auto Rerun¶
These are two settings that are primarily intended for realtime datamodels, but any datamodel can be configured to use these options.
Generally speaking, the following holds true:
- Conflate Run
-
- Approximately the minimum amount of time between reruns
- Prevents a datasource from being repeatedly hit within a given time
- Prevents the datamodel being invoked from other external sources within the conflate time (e.g
reprocess())
- Auto Rerun
-
- Approximately the maximum amount of time between reruns
- Causes the datamodel to reprocess every time
- If both "Conflate Run" and "Auto Rerun" is set, the conflate conditions must be met first